
Lab 11: Face Recognition
The goal of this lab is to implement face recognition using Principal Component Analysis (PCA). One of the most important applications of the PCA is mapping a dataset into a new space with smaller dimension in a way that minimizes the reconstruction error. Dimensionality reduction is specially useful for datasets in which the dimension of each sample points is large, as in the case of images.
• Click here to download the assignment.
• Click here to download the data for the assignment.
Creating Training and Test Sets
One of the most important concepts in statistics and machine learning is that of training and testing sets. The question we’re trying to address is how to test our methods in a “realistic” scenario. That is, after we’ve trained our algorithm, it has to work on images it hasn’t seen yet, i.e., on new faces. So to know how well it’ll do in practice, we need to test it on new faces and not on faces we’ve used to train it. How do we do that?
Instead of using all the data we have available, we’re going to separate it into two parts: the training set contains the pictures of faces we will use to develop our algorithm; the test set contains the pictures of faces we will use to test it. Notice that both of them come from the labeled picture set we have, but during testing we’ll hide the labels, try to guess them, and then compare with the true label to see how we did. The most important thing is that we are never allowed to use any picture from the test set during training, only for testing.
Here, we are then going to create a matrix $X_{\text{train}}$ containing the faces of the training set — one per column — as well as a vector $y_{\text{train}}$ containing the label of each column, that is, the person whom that face belongs to. Note that the lab doesn’t ask for the $y$, but having a vector with the labels of each column will make the next parts of the lab easier. Similarly, we will also create a matrix $X_{\text{test}}$ and a vector $y_{\text{test}}$ with the (vectorized) faces of the test set and their labels, respectively. The dataset is organized as follows: each of the 40 individuals has a folder and inside their folder there are 10 different gray scale pictures of their faces. So here we need to:
- Get into the $i^{\text{th}}$ individual’s folder.
- Import the first 9 pictures and save them to $X_{\text{train}}$.
- Import the last picture and save it to $X_{\text{test}}$.
- Fill $y_{\text{train}}$ and $y_{\text{test}}$ with $i$.
In Python, we can implement those steps as follows. First, we create matrices $X_{\text{train}}$ and $X_{\text{test}}$ to store the samples used in the training and test sets, respectively. Then, since all subfolders are named $\p{si}$, $i = 1, \dots, 40$ , and all the images are named $\p{j.pmg}$, with $j = 1, \dots, 10$, we can use a standard $\p{for}$ loop to find the location of the image we want to import. Once we have that location, we can use the $\p{imread}$ function from the $\p{matplotlib.image}$ library to import that image. Next, we vectorize the image and save it in the corresponding column of $X_{\text{train}}$ or $X_{\text{test}}$. To keep track of whom that face belongs to, we also save the corresponding label to the vectors $y_{\text{train}}$ and $y_{\text{test}}$.
import numpy as np
import matplotlib.image as mpimg
class training_test_sets():
def __init__(self, num_samples, im_set_path):
self.num_samples = num_samples
self.num_test_samples = 10 - num_samples
self.im_set_path = im_set_path
self.X_train = np.zeros((10304,40*num_samples))
self.y_train = np.zeros(40*num_samples)
self.X_test = np.zeros((10304,40*self.num_test_samples))
self.y_test = np.zeros(40*self.num_test_samples)
def solve(self):
for ii in range(40):
for jj in range(self.num_samples):
im_path = self.im_set_path + '/s' + str(ii+1) + '/' + str(jj+1) + '.pgm'
cur_img = mpimg.imread(im_path)
self.X_train[:, ii*self.num_samples + jj] = np.ravel(cur_img)
self.y_train[ii*self.num_samples + jj] = int(ii + 1)
for jj in range(self.num_test_samples):
im_path = self.im_set_path + '/s' + str(ii+1) + '/' + str(jj+10) + '.pgm'
cur_img = mpimg.imread(im_path)
self.X_test[:, ii*self.num_test_samples + jj] = np.ravel(cur_img)
self.y_test[ii*self.num_test_samples + jj] = int(ii + 1)
return self.X_train, self.y_train, self.X_test, self.y_test
PCA on the Training and Test Sets
Last week, we used the sample average
\begin{equation} \bar{\bbx} = \frac{1}{M} \sum_{m = 1}^M \bbx_m \end{equation}
and the sample covariance matrix
\begin{equation} \Sigma = \frac{1}{M} \sum_{m = 1}^M (\bbx_m – \bar{\bbx}) (\bbx_m – \bar{\bbx})^T \end{equation}
to define the PCA transform. We did that by using the eigenvectors $\bbv_0, \bbv_1, \dots$ of the sample covariance matrix $\Sigma$ ordered according to the eigenvalues $\lambda_0 \geq \lambda_1 \geq \dots \geq \lambda_{N-1}$ to define a unitary matrix
\begin{equation} \bbP = [\bbv_0 \bbv_1 \dots \bbv_{N-1}] \in \mathbb{R}^{N \times N}.\end{equation}
That matrix allows us to write the PCA transform and its inverse as
\begin{equation}\begin{aligned}\bbX^{\text{PCA}} &= \bbP^H(\bbx – \bar{\bbx}) \\\bbx &= \bbP \bbX^{\text{PCA}} + \bar{\bbx}.\end{aligned}\end{equation}
But now, we want to do dimensionality reduction by truncating (“low-pass filtering”) this transform. We could take the whole PCA then discard the components that we don’t need, but that’s not very efficient. Instead, we compute the coefficients we want by slicing the PCA. If we only care about the first $k$ coefficients, we define
\begin{equation} \bbP = [\bbv_0 \bbv_1 \dots \bbv_{k-1}] \in \mathbb{R}^{N \times k} \end{equation}
and use the partial PCA transform
\begin{equation} \begin{aligned}\bbX^{\text{PCA}_k} &= \bbP_k^H(\bbx – \bar{\bbx}) \\ \tilde{\bbx} &= \bbP_k \bbX^{\text{PCA}_k} + \bar{\bbx}. \end{aligned} \end{equation}
Here, we will then use the training set we created earlier to define a partial PCA transform. Given $X_{\text{train}}$, we can compute the sample mean and the sample covariance of the data set. Once we have those, we can compute the eigendecomposition of the sample covariance matrix, and retain the first $k$ eigenvectors — recall that those are the directions in which the data varies the most. Then, $\bbP_k$ is simply given by the aggregation of those eigenvectors, and we can compute the partial PCA transform as defined above.
class training_set_PCA():
def __init__(self, X_train, k):
self.X_train = X_train
self.k = k
def solve(self):
N, n_faces = self.X_train.shape
mu = self.X_train.mean(axis=1)
X = np.zeros((N, n_faces))
for ii in range(n_faces):
X[:, ii] = self.X_train[:, ii] - mu
sigma = np.matmul(X, X.transpose())
sigma /= n_faces
_, sigma_eigs = scipy.sparse.linalg.eigs(sigma, k=self.k)
P_H = np.conj(np.transpose(sigma_eigs))
X_pca = np.matmul(P_H, X)
return mu, sigma_eigs, X_pca
Given $\bbP_k$ and the sample mean of the dataset, computing the partial PCA transform of the images in the test set is straightforward.
class test_set_PCA():
def __init__(self, mu, P, X_test):
self.X_test = X_test
self.mu = mu
self.P = P
def solve(self):
N, n_faces = self.X_test.shape
X = np.zeros((N, n_faces))
for ii in range(n_faces):
X[:, ii] = self.X_test[:, ii] - self.mu
P_H = np.conj(np.transpose(self.P))
X_pca = np.matmul(P_H, X)
return X_pca
Nearest Neighbor Classification
The idea behind the nearest neighbor classifier in this setting is to take a transformed test point, $X_{\text{test}}^{\text{PCA}_k}$, and compare it to (the PCA transform of) each training point $X_{\text{train},i}^{\text{PCA}_k}$ using the Euclidean norm. Once we find the closest point, then we assign the label of that point to the test sample. Note that, in order to test our classifier, we need to do the classification not for a single input vector, but for the whole test set. We could do that by simply using nested $\p{for}$ loops, but the $\p{scipy}$ library has a function that does this computation in a parallelized fashion for us: $\p{cdist}$. Just keep in mind that $\p{cdist}$ assumes the data are in the rows and our matrices have data in the columns. After computing the distances between the samples from the test set and each training point, we’ll use $\p{np.argmin}$ to find the index that has the smallest distance in each column, as shown in the code snippet below.
class nearest_neighbors_classifier():
def __init__(self, X_train, X_test):
self.X_train = X_train
self.X_test = X_test
def solve(self):
distances = scipy.spatial.distance.cdist(self.X_train.transpose(), self.X_test.transpose())
predicted_labels = np.argmin(distances, axis=0)
return predicted_labels
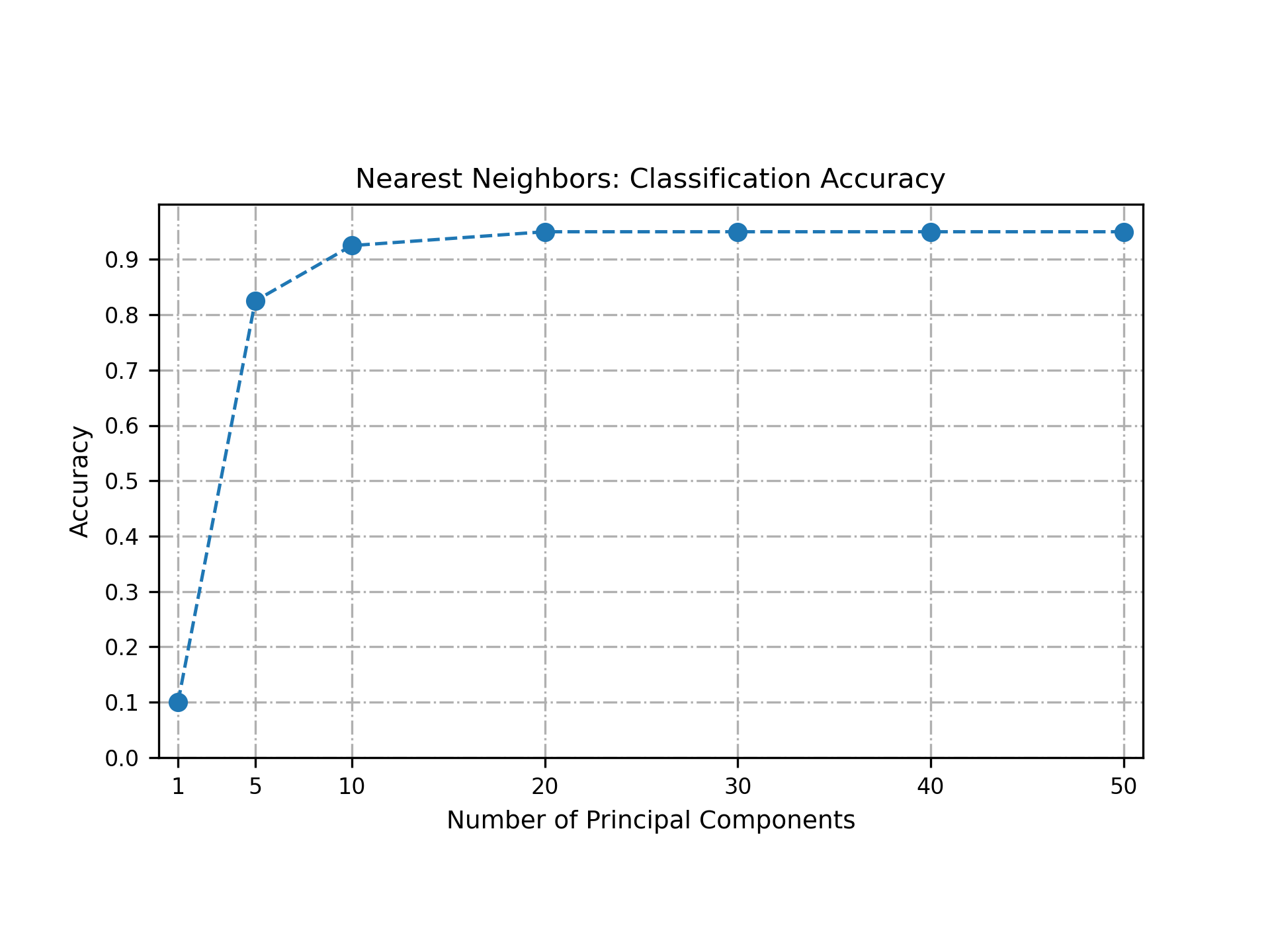
We can then use the prediction output by the nearest neighbor class to estimate the classification accuracy for different values of $k$.
accuracy = np.mean(training_labels[predicted_labels] == test_labels)
As we can see in the plot below, we can obtain fairly good classification accuracies despite using only a few components to represent the images in the training and test sets.
Code links
The code used to implement the steps above can be downloaded from ESE224_LAB11.